
Synthetic data generation is the process of creating artificial data that is designed to mimic real-world data. It is often used in machine learning and data science applications to augment or supplement existing datasets, or to generate data for testing and validation purposes.
Why is Synthetic Data Generation Needed?
There are several reasons why synthetic data generation may be needed:
- Cold Start Problem: The cold start problem refers to the difficulty of training machine learning models when little or no training data is available. This can be a challenge in many real-world applications, as it is often difficult to collect sufficient amounts of labeled data. One way to address the cold start problem is to use synthetic data generation. Synthetic data can be used to augment the available real data, allowing the model to learn from a larger dataset and improve its performance.
- Data privacy and protection: In some cases, it may not be possible or ethical to use real-world data for certain tasks due to privacy or security concerns. Synthetic data can be used as an alternative that preserves the characteristics of the original data while protecting sensitive information.
- Data scarcity: In some fields, it may be difficult or expensive to collect real-world data. Synthetic data can be used to supplement existing datasets or to generate data for tasks where real-world data is scarce.
Ways to Generate Synthetic Data
There are several approaches to synthetic data generation, depending on the type of data being generated. Here are a few examples:
Image Data
One popular approach to generating synthetic images is through the use of generative models like:
- Generative adversarial networks (GANs): They consist of two networks – a generator and a discriminator. The goal of the generator is to create synthetic images matching the training data sets, while the goal of the discriminator is to determine whether the images are real or synthetic. The two are trained together in push-pull format. Eventually the trained generator is used to generate more images.
- Variational autoencoders (VAEs). VAEs are another type of neural network that can be used to generate synthetic images. They consist of an encoder and a decoder. The encoder maps the input data to a latent space, while the decoder maps the latent space back to the original data space. VAEs can be used to generate synthetic images by sampling from the latent space and passing the samples through the decoder.
- Diffusion based models: Diffusion-based models can be used to generate images by starting with a random initial state and then simulating the diffusion process over time. The final state of the diffusion process can be interpreted as an image. To use diffusion-based models for image generation, you will need to specify the parameters of the diffusion process, such as the diffusion coefficient and the time step. You will also need to specify the initial state of the diffusion process, which can be a random noise image or an image from the training data.
Additionally, for some tasks computer graphics-based data augmentation techniques can be used.. This can involve generating new images by altering or combining existing images, or by synthesising new images from scratch. There are tools like blender, unity which can be employed to generate physics based realistic scenarios.
Tabular Data
TensorFlow Probability is a library that provides tools for generating synthetic tabular data. It allows users to specify the distribution of the data and sample synthetic data from it. Here is an example of how you can use TensorFlow Probability to generate synthetic data:
import tensorflow_probability as tfp
import tensorflow as tf
# Set the random seed for reproducibility
tf.random.set_seed(123)
# Specify the distribution of the data
distribution = tfp.distributions.Normal(loc=0., scale=1.)
# Sample synthetic data from the distribution
synthetic_data = distribution.sample(sample_shape=[1000])Below you can see the result of data generated:
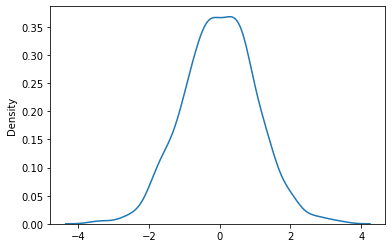
In this example, we are generating synthetic data from a normal distribution with a mean of 0 and a standard deviation of 1. The sample method is used to sample synthetic data from the distribution. The sample_shape argument specifies the shape of the samples, in this case a batch of 1000 samples.
TensorFlow Probability provides a wide range of distributions that you can use to generate synthetic data. You can also use custom distributions by defining a subclass of tfp.distributions.Distribution. TensorFlow probability can be very useful in solving the cold-start problem in AI- where we have no data.
In addition to sampling synthetic data, TensorFlow Probability also provides tools for manipulating and transforming the data, such as transforming data from one distribution to another and sampling from the transformed distribution.
Additionally, if you have sufficient training data you can use it to train generative models like GANs/VAEs and diffusion models. To use generative models to generate tabular data, you will need to specify the type of model you want to use and train it on real tabular data. Once the model is trained, you can sample synthetic data from it by specifying the number of samples you want to generate and the input parameters for the generator or decoder. It is important to note that generative models can be computationally expensive to train, and they may require a large amount of real data to learn the underlying distribution of the data. In some cases, it may not be feasible to use generative models to generate tabular data if the available data is limited.
Textual Data
Synthetic text data can be generated using generative text models such transformer models- BERT, GPT-2, RoBERTa etc. These models are trained on large datasets of real text and are able to generate new text that follows the style and content of the training data. They can generate text by predicting the next word in a sequence given a prompt. Here is an example of how you can use BERT to generate text using the transformers library in Python:
from transformers import pipeline
import torch
text_generation = pipeline('text-generation')
# Set the prompt for the text generation
prompt = "The earth is"
generated_text= text_generation(prompt, max_length=50, do_sample=True)[0]
print(generated_text['generated_text'])And the generated text is:
The earth is made up of several layers, with all the material inside in one layer connected by a series of tunnels. The most famous is called “Utopia” and is connected to the rest of the earth by a series of tunnels.
– OpenAI GPT2
It is important to note that pre-trained transformer models like BERT are large and computationally expensive to fine-tune and use. You may need to use a GPU or a cloud computing platform to fine-tune and use these models. You should also carefully choose the model and the dataset to fine-tune it on to ensure that the generated text is of high quality and relevance to your task.
You can also use OpenAI GPT3 API to generate text. GPT-3 (Generative Pre-trained Transformer 3) is a large language model developed by OpenAI that can be used to generate synthetic text data. It is trained on a massive dataset and can generate human-like text by predicting the next word in a sequence given a prompt.
To use GPT-3 to generate textual data, you will need to sign up for an OpenAI API key and install the openai Python library. You can then use the openai.Completion.create function to generate text using GPT-3.
Here is an example of how you can use GPT-3 to generate text using the Python API:
import openai
# Set the OpenAI API key
openai.api_key = 'Your-API-Key'
# Set the prompt for the text generation
prompt = "The earth is"
# Generate text using GPT-3
completion = openai.Completion.create(model="code-davinci-002", prompt=prompt, max_tokens=50)
print(completion['choices'][0].text)The result:
an ideal breeding ground for books. I may well drive. My friends left the town for good. Last year was a period of economic uncertainty.
– OpenAI GPT3
GPT-3 provides a range of options for controlling the generation of text, such as the length of the generated text, the temperature of the sampling process, and the inclusion of punctuation. It is important to note that GPT-3 is a large and powerful language model, and it can be computationally expensive to use. You will need to pay for usage of the API, and you may need to limit the number of requests you make to avoid running up large bills.
If you need any help with synthetic data generation, or if you have any questions about the process, feel free to contact NePeur. We specialise in helping organisations make the most of artificial intelligence and machine learning, and we would be happy to assist you with your data generation needs.
Maximize the Potential of AI in Your Business with NePeur’s Specialized Services
At NePeur, we understand the potential of AI in today’s business landscape. That’s why we offer a range of services to help companies like yours harness the power of AI. Our services include:
- Data Analytics: We help you assess the quality and quantity of your data, and identify and address any biases present.
- AI Consultancy: We work with business leaders to create a comprehensive AI strategy and identify the best use cases for your business.
- Custom AI Model Building: We can design and build high-efficiency, calibrated, and fair AI models tailored to your specific needs.
- AI Training for Leaders: Our custom training courses empower founders and investors of AI startups to understand the business procedures necessary for success.
- Up-skilling Your Staff: We can organize specialized training for your employees to help them master specific areas of AI, such as computer vision, natural language processing, and reinforcement learning.
If you’re ready to take your business to the next level with AI, contact NePeur today to learn more about our services and how we can help you achieve your goals
Book an appointment today